WARNING: Detailed technical article
Why is it important to apply filters and slicers correctly in BI Helper?
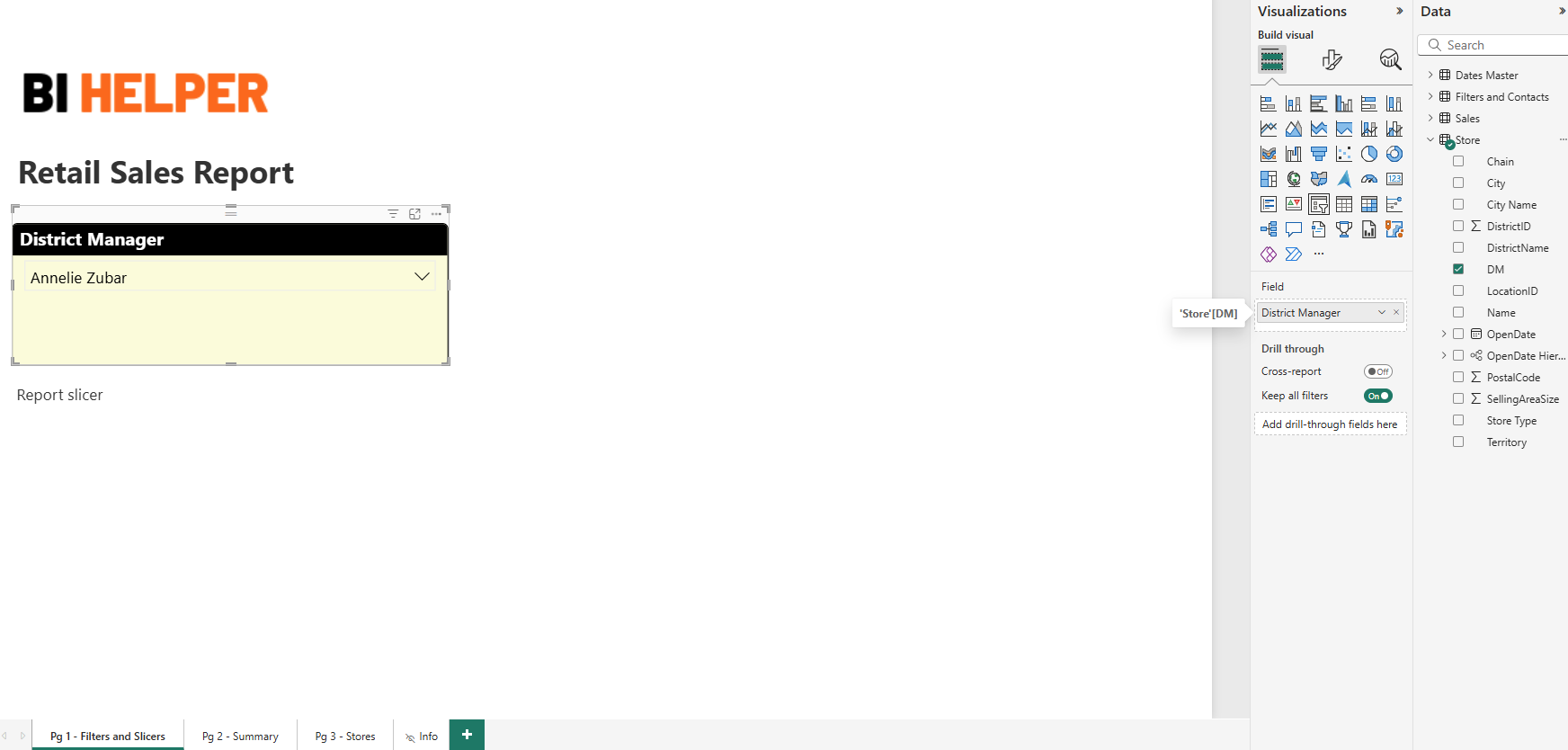
Applying filters and slicers to create and distribute user-specific PDF/ PPTX reports is the core function of BI Helper.
Users occasionally face an issue where filters or slicers selected by them in Power BI are not applied consistently in the BI Helper output, resulting in some visuals being unfiltered (all slicer/ filter values applied) or incorrectly filtered. This is a serious data security and privacy issue that needs to be addressed immediately.
An offshoot of this problem is a PDF/ PPTX with blank pages or visuals.
How do I diagnose a filter/ slicer issue in BI Helper?
Filter/ slicer issues can occur in one of three areas:
This article provides a checklist for the input of filters and slicers in BI Helper. The checklist also helps diagnose and resolve any filter/ slicer issues in a BI Helper job.
This checklist addresses filter and slicer mismatch caused due to the interaction of Power BI and BI Helper, i.e., the proper application of filter and slicer syntax in BI Helper.
This section covers problems with the data model, cross-filtering, visual interaction or input error causing filter and slicer mismatch in the BI Helper output.
The diagnostics and solutions in this section help make your Power BI reports robust and error-free. They are upstream of BI Helper and need to be addressed in Power BI.
The result is blank pages or visuals in the BI Helper snapshot of the Power BI report. Or the prior filter or slicer value may persist in a snapshot, resulting in a mismatch. The problem is amplified as the frequency of data loads or Power BI refreshes increases.
Solution: Simplify your Power BI report (PBIX file) and reduce its size to 300 MB or less. Or create a separate ‘lite’ version for BI Helper.
Solution: Use columns with unique values as filter and slicer inputs to BI Helper.
Caching in Power BI Service occurs randomly (and very rarely) and results in a slicer value not getting cleared from all the pages/ visuals before the next value is applied. There is no consistency across batches on which slicer values, pages or visuals are applied correctly and which ones carry forward from the prior PDF/ PPTX.
Fortunately, this 'corruption' of the Microsoft Azure cache is very rare. We have only observed it 2-3 times in tens of thousands of BI Helper job runs. Further, this error is only observed with slicers, not with filters.
The bad news is that there is no way to detect this issue. BI Helper reads and applies slicer values ONLY on the first page of the Power BI report and takes snapshots of all subsequent pages assuming that the slicer value has carried through.
Solution:
If your slicer mismatch problem persists after you apply all the above steps, consider replacing your slicers with report level filters (Filters pane > Filters on all pages).
Slicer mismatch due to Azure caching is sometimes seen in BI Helper PDF/ PPTX files and not in the files using the Export to File option in Power BI Service. This is because the Export to File Power BI REST API is not supported for Power BI Pro and PPU users, so BI Helper uses a different Power BI API to create PDF/ PPTX files.
Note: With the Export to File option, users have to manually generate one output report at a time, change filter and slicer values each time, and then manually email each one to the right users. As the report volume increases, this is not a viable process.
Even with Power BI Premium capacity, automated PDF export has the limitations detailed in the following link Export Power BI embedded analytics reports API - Power BI | Microsoft Learn.
Limitations include semantic models being supported only on Power BI Premium or Embedded capacity, 250 MB output file size, and 50 exports per API call. Composite semantic models with at least one external data source with SSO are not supported.
That is why Power BI Premium customers often use BI Helper for their report bursting requirements, instead of their liccensed Power BI Premium/ Fabric capacity.